
Chapter 6: Advanced Convolutional Neural Networks¶
By Tomas Beuzen 🚀

Chapter Outline¶
Chapter Learning Objectives¶
Load image data using
torchvision.datasets.ImageFolder()to train a network in PyTorch.Explain what “data augmentation” is and why we might want to do it.
Be able to save and re-load a PyTorch model.
Tune the hyperparameters of a PyTorch model using Ax.
Describe what transfer learning is and the different flavours of it: “out-of-the-box”, “feature extractor”, “fine tuning”.
Imports¶
import json
import numpy as np
import pandas as pd
from collections import OrderedDict
import torch
import torchvision
from torch import nn, optim
from torchvision import transforms, models, datasets
from torchsummary import summary
from PIL import Image
import memory_profiler # conda install -c anaconda memory_profiler
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from utils.plotting import *
1. Datasets, Dataloaders, and Transforms¶
1.1. Preparing Data¶
torch and torchvision provide out-of-the-box functionality for loading in lots of different kinds of data. The way you create a dataloader depends on the data you have (i.e., do you have numpy arrays, tensors, images, or something else?) and the PyTorch docs can help you out
Loading data into PyTorch is usually a two-step process:
Create a
dataset(this is your raw data)Create a
dataloader(this will help you batch your data)
Working with CNNs and images, you’ll mostly be using torchvision.datasets.ImageFolder() (docs), it’s very easy to use. It assumes you have a directory structure with sub-directories for each class like this:
data
│
├── class_1
│ ├── image_1.png
│ ├── image_2.png
│ ├── image_3.png
│ └── etc.
└── class_2
├── image_1.png
├── image_2.png
├── image_3.png
└── etc.
For example, consider the training dataset I have in the current directory at Chapters/data/bitmoji_rgb:
bitmoji_rgb
└── train
├── not_tom
│ ├── image_1.png
│ ├── image_2.png
│ ├── image_3.png
│ └── etc.
└── tom
├── image_1.png
├── image_2.png
├── image_3.png
└── etc.
TRAIN_DIR = "data/bitmoji_rgb/train/"
mem = memory_profiler.memory_usage()[0]
train_dataset = torchvision.datasets.ImageFolder(root=TRAIN_DIR)
print(f"Memory consumed: {memory_profiler.memory_usage()[0] - mem:.0f} mb")
Memory consumed: 0 mb
Notice how our memory usage is the same, we aren’t loading anything in yet, just making PyTorch aware of what kind of data we have and where it is. We can now check various information about our train_dataset:
print(f"Classes: {train_dataset.classes}")
print(f"Class count: {train_dataset.targets.count(0)}, {train_dataset.targets.count(1)}")
print(f"Samples:",len(train_dataset))
print(f"First sample: {train_dataset.samples[0]}")
Classes: ['not_tom', 'tom']
Class count: 857, 857
Samples: 1714
First sample: ('data/bitmoji_rgb/train/not_tom/bitmoji_10187.png', 0)
Now, we could start working with this dataset directly. For example, here’s the first sample:
img, target = next(iter(train_dataset))
print(f"Class: {train_dataset.classes[target]}")
img
Class: not_tom

But often we want to apply some pre-processing to our data. For example, ImageFolder loads our data using the PIL package, but we need tensors!
print(f"Image data type: {type(img)}")
print(f" Image size: {img.size}")
Image data type: <class 'PIL.Image.Image'>
Image size: (128, 128)
Any pre-processing we wish to apply to our images is done using torchvision.transforms. There are a lot of transformation options here - we’ll explore some more later - for now, we’ll Resize() our images and convert them ToTensor(). We use transforms.Compose() to chain multiple transformations together:
IMAGE_SIZE = 64
data_transforms = transforms.Compose([
transforms.Resize(IMAGE_SIZE),
transforms.ToTensor()
])
train_dataset = torchvision.datasets.ImageFolder(root=TRAIN_DIR,
transform=data_transforms)
img, target = next(iter(train_dataset))
print(f"Image data type: {type(img)}")
print(f" Image size: {img.shape}")
Image data type: <class 'torch.Tensor'>
Image size: torch.Size([3, 64, 64])
Okay cool, but there’s one more issue: we want to work with batches of data, because most of the time, we won’t be able to fit an entire dataset into RAM at once (especially when it comes to image data). This is where PyTorch’s dataloader comes in. It allows us to specify how we want to batch our data:
BATCH_SIZE = 64
mem = memory_profiler.memory_usage()[0]
train_loader = torch.utils.data.DataLoader(train_dataset, # our raw data
batch_size=BATCH_SIZE, # the size of batches we want the dataloader to return
shuffle=True, # shuffle our data before batching
drop_last=False) # don't drop the last batch even if it's smaller than batch_size
print(f"Memory consumed: {memory_profiler.memory_usage()[0] - mem:.0f} mb")
Memory consumed: 0 mb
Once again, we aren’t loading anything yet, we just prepared the loader. We can now query the loader to return a batch of data (this will consume memory):
mem = memory_profiler.memory_usage()[0]
imgs, targets = next(iter(train_loader))
print(f" # of batches: {len(train_loader)}")
print(f" Image data type: {type(imgs)}")
print(f" Image batch size: {imgs.shape}") # dimensions are (batch size, image channels, image height, image width)
print(f" Target batch size: {targets.shape}")
print(f" Batch memory: {memory_profiler.memory_usage()[0] - mem:.2f} mb") # memory usage after loading batch
# of batches: 27
Image data type: <class 'torch.Tensor'>
Image batch size: torch.Size([64, 3, 64, 64])
Target batch size: torch.Size([64])
Batch memory: 0.14 mb
1.2. Saving and Loading PyTorch Models¶
The PyTorch documentation about saving and loading models is fantastic and the process is very easy. It’s common PyTorch convention to save models using either a .pt or .pth file extension. It is recommended that you just save your model learned parameters from model.state_dict():
# Save model
PATH = "models/my_model.pt"
torch.save(model.state_dict(), PATH) # save model at PATH
# Load model
model = MyModelClass() # create an instance of the model
model.load_state_dict(torch.load(PATH)) # load model from PATH
If you’re using the model for inference (not training), make sure to switch it to eval mode: model.eval(). There are other options for saving models, in particular, if you want to save a model and continue training it later, you’ll want to save other necessary information like the optimizer state, the epoch you’re on, etc. This is all documented here in the PyTorch docs.
Let’s see an example of a model I saved earlier:
class bitmoji_CNN(nn.Module):
def __init__(self):
super().__init__()
self.main = nn.Sequential(
nn.Conv2d(3, 8, (5, 5)),
nn.ReLU(),
nn.MaxPool2d((2, 2)),
nn.Conv2d(8, 4, (3, 3)),
nn.ReLU(),
nn.MaxPool2d((3, 3)),
nn.Flatten(),
nn.Linear(324, 128),
nn.ReLU(),
nn.Linear(128, 1)
)
def forward(self, x):
out = self.main(x)
return out
PATH = "models/bitmoji_cnn.pt"
model = bitmoji_CNN()
model.load_state_dict(torch.load(PATH))
model.eval()
bitmoji_CNN(
(main): Sequential(
(0): Conv2d(3, 8, kernel_size=(5, 5), stride=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(8, 4, kernel_size=(3, 3), stride=(1, 1))
(4): ReLU()
(5): MaxPool2d(kernel_size=(3, 3), stride=(3, 3), padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=324, out_features=128, bias=True)
(8): ReLU()
(9): Linear(in_features=128, out_features=1, bias=True)
)
)
1.3. Data Augmentation¶
Data augmentation is used for two main purposes:
Make your CNN more robust to scale/rotation/translation in your images
Increase the size of your training set
Let’s explore point 1 a bit further. We can see below is a Bitmoji of me, does the CNN I loaded above predict this?
image = Image.open('img/tom-bitmoji.png')
image

IMAGE_SIZE = 64
image_tensor = transforms.functional.to_tensor(image.resize((IMAGE_SIZE, IMAGE_SIZE))).unsqueeze(0)
prediction = int(torch.sigmoid(model(image_tensor)) > 0.5)
print(f"Prediction: {train_dataset.classes[prediction]}")
Prediction: tom
Looks good! But what happens if I flip my image. You can still tell it’s me, but can my CNN?
image = image.rotate(180)
image

image_tensor = transforms.functional.to_tensor(image.resize((IMAGE_SIZE, IMAGE_SIZE))).unsqueeze(0)
prediction = int(torch.sigmoid(model(image_tensor)) > 0.5)
print(f"Prediction: {train_dataset.classes[prediction]}")
Prediction: not_tom
Well that’s problematic. We’d like our CNN to be robust against these kinds of differences. We can expose our CNN to flipped images, so that it can learn to better predict them, with data augmentation. Common image augmentations include:
rotation/flipping
cropping
adding noise
You can view others in the PyTorch docs
We add transforms just like we did previously, using the transform argument of torchvision.datasets.ImageFolder():
data_transforms = transforms.Compose([
transforms.RandomVerticalFlip(p=0.5),
transforms.RandomRotation(degrees=20),
transforms.Resize(IMAGE_SIZE),
transforms.ToTensor()
])
train_dataset = torchvision.datasets.ImageFolder(root=TRAIN_DIR,
transform=data_transforms)
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
drop_last=False)
sample_batch, target = next(iter(train_loader))
plot_bitmojis(sample_batch, rgb=True)

Here’s a model I trained earlier using the above augmentations (see Appendix D: Creating a CNN to Predict Bitmojis for the full code):
PATH = "models/bitmoji_cnn_augmented.pt"
model = bitmoji_CNN()
model.load_state_dict(torch.load(PATH))
model.eval();
Let’s try it out on the flipped image:
image

image_tensor = transforms.functional.to_tensor(image.resize((IMAGE_SIZE, IMAGE_SIZE))).unsqueeze(0)
prediction = int(torch.sigmoid(model(image_tensor)) > 0.5)
print(f"Prediction: {train_dataset.classes[prediction]}")
Prediction: tom
Now we got it!
1.4. Batch Normalization¶
Earlier in the course, we saw how normalizing the inputs to our neural network can help our optimization (by making sure the scale of one feature doesn’t overwhelm others). But what about the hidden layers of our network? They also have data flowing into them and parameters to optimize, can we normalize them too to make optimization better? Sure can! Batch normalization is the normalization of data in hidden layers.
It is usually applied after the activation function of a hidden layer (but it doesn’t have to be):
Where:
\(z\) = the output of your hideen layers before the activation function
\(\mu = \frac{1}{n}\sum_{i=1}^{n}z_i\) (i.e., the mean of \(z\))
\(\sigma^2 = \frac{1}{n}\sum_{i=1}^{n}(z_i-\mu)^2\) (i.e, the variance of \(z\))
Batch normalization can help stabilize and speed up optimization, make your network more invariant to changes in the training distribution, and often has a slight regularization effect. See this video by Andrew Ng if you want to learn more about the details.
2. Hyperparameter Tuning¶
With neural networks we potentially have a lot of hyperparameters to tune:
Number of layers
Number of nodes in each layer
Activation functions
Regularization
Initialization (starting weights)
Optimization hyperparams (learning rate, momentum, weight decay)
etc.
With so many parameters, a grid-search approach to optimization is not feasible. Luckily, there are many packages out there that make neural network hyperparameter tuning fast and easy:
We’ll be using Ax, created by Facebook (just like PyTorch):
pip install ax-platform
Below, I’ve adapted a tutorial from their docs:
from ax.service.managed_loop import optimize
from ax.plot.contour import plot_contour
from ax.plot.trace import optimization_trace_single_method
from ax.utils.notebook.plotting import render, init_notebook_plotting
First, I’ll create some simple training and validation loaders:
TRAIN_DIR = "data/bitmoji_rgb/train/"
VALID_DIR = "data/bitmoji_rgb/valid/"
IMAGE_SIZE = 64
BATCH_SIZE = 128
# Transforms
data_transforms = transforms.Compose([transforms.Resize(IMAGE_SIZE), transforms.ToTensor()])
# Load data and create dataloaders
train_dataset = torchvision.datasets.ImageFolder(root=TRAIN_DIR, transform=data_transforms)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
valid_dataset = torchvision.datasets.ImageFolder(root=VALID_DIR, transform=data_transforms)
valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=BATCH_SIZE, shuffle=True)
# GPU available?
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using: {device}")
# Model
model = bitmoji_CNN()
model.to(device);
Using: cpu
Now, we need a training function. This function will be re-run multiple times throughout the hyperparameter optimization process, as we wish to train the model on different hyperparameter configurations. The argument parameters is a dictionary containing the hyperparameters we wish to tune:
def train(model, train_loader, hyperparameters, epochs=20):
"""Training wrapper for PyTorch network."""
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(),
lr=hyperparameters.get("lr", 0.001),
betas=(hyperparameters.get("beta1", 0.9), 0.999))
for epoch in range(epochs):
for X, y in train_loader:
if device.type == 'cuda':
X, y = X.to(device), y.to(device)
optimizer.zero_grad()
y_hat = model(X).flatten()
loss = criterion(y_hat, y.type(torch.float32))
loss.backward()
optimizer.step()
return model
We also need an evaluate() function that reports how well our model is doing on some validation data. This will also be called multiple times during the hyperparameter optimization:
def evaluate(model, valid_loader):
"""Validation wrapper for PyTorch network."""
model.eval()
accuracy = 0
with torch.no_grad(): # this stops pytorch doing computational graph stuff under-the-hood and saves memory and time
for X, y in valid_loader:
if device.type == 'cuda':
X, y = X.to(device), y.to(device)
y_hat = model(X).flatten()
y_hat_labels = torch.sigmoid(y_hat) > 0.5
accuracy += (y_hat_labels == y).type(torch.float32).mean().item()
accuracy /= len(valid_loader) # avg accuracy
return accuracy
Let’s make sure our evaluation function is working:
evaluate(model, valid_loader)
0.46875
Looks good! The accuracy is bad right now because we haven’t trained our model yet.
We now need a wrapper function that puts everything together. Basically each iteration of hyperparameter optimization (i.e., each time we try a new set of hyperparameters), this function is executed. It trains the model using the given hyperparameters, and then evaluates the model’s performance:
def train_evaluate(parameterization):
model = bitmoji_CNN()
model.to(device)
model = train(model, train_loader, hyperparameters=parameterization)
return evaluate(model, valid_loader)
Finally, we use optimize() to run Bayesian optimization on a hyperparameter dictionary. I ran this on a GPU and have included the output below:
best_parameters, values, experiment, model = optimize(
parameters=[
{"name": "lr", "type": "range", "bounds": [1e-6, 0.4], "log_scale": True, "value_type": 'float'},
{"name": "beta1", "type": "range", "bounds": [0.5, 0.999], "value_type": 'float'},
],
evaluation_function=train_evaluate,
objective_name='accuracy',
total_trials = 20
)
[INFO 01-28 17:25:27] ax.modelbridge.dispatch_utils: Using Bayesian Optimization generation strategy: GenerationStrategy(name='Sobol+GPEI', steps=[Sobol for 5 trials, GPEI for subsequent trials]). Iterations after 5 will take longer to generate due to model-fitting.
[INFO 01-28 17:25:27] ax.service.managed_loop: Started full optimization with 20 steps.
[INFO 01-28 17:25:27] ax.service.managed_loop: Running optimization trial 1...
[INFO 01-28 17:26:28] ax.service.managed_loop: Running optimization trial 2...
[INFO 01-28 17:27:25] ax.service.managed_loop: Running optimization trial 3...
[INFO 01-28 17:28:20] ax.service.managed_loop: Running optimization trial 4...
[INFO 01-28 17:29:13] ax.service.managed_loop: Running optimization trial 5...
[INFO 01-28 17:30:06] ax.service.managed_loop: Running optimization trial 6...
[INFO 01-28 17:31:01] ax.service.managed_loop: Running optimization trial 7...
[INFO 01-28 17:31:57] ax.service.managed_loop: Running optimization trial 8...
[INFO 01-28 17:32:52] ax.service.managed_loop: Running optimization trial 9...
[INFO 01-28 17:33:46] ax.service.managed_loop: Running optimization trial 10...
[INFO 01-28 17:34:41] ax.service.managed_loop: Running optimization trial 11...
[INFO 01-28 17:35:36] ax.service.managed_loop: Running optimization trial 12...
[INFO 01-28 17:36:30] ax.service.managed_loop: Running optimization trial 13...
[INFO 01-28 17:37:25] ax.service.managed_loop: Running optimization trial 14...
[INFO 01-28 17:38:20] ax.service.managed_loop: Running optimization trial 15...
[INFO 01-28 17:39:15] ax.service.managed_loop: Running optimization trial 16...
[INFO 01-28 17:40:08] ax.service.managed_loop: Running optimization trial 17...
[INFO 01-28 17:41:03] ax.service.managed_loop: Running optimization trial 18...
[INFO 01-28 17:41:59] ax.service.managed_loop: Running optimization trial 19...
[INFO 01-28 17:43:01] ax.service.managed_loop: Running optimization trial 20...
best_parameters
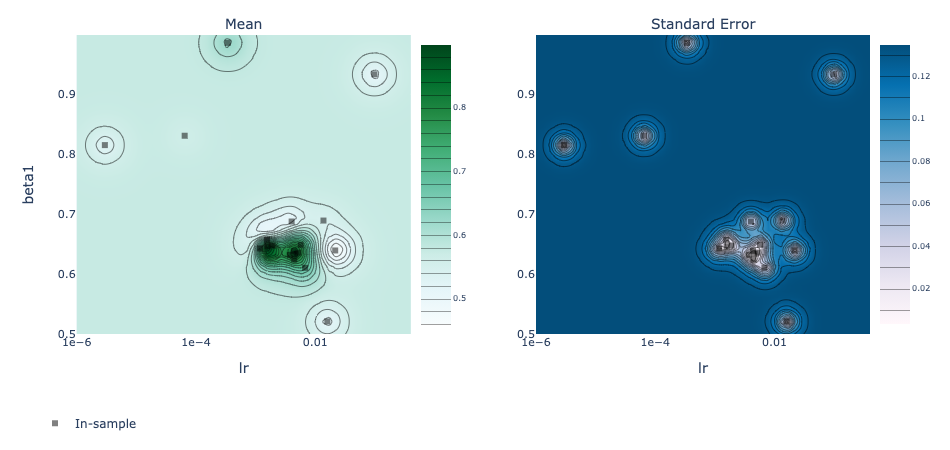
{'lr': 0.0015762617170424081, 'beta1': 0.6464455205729447}
means, covariances = values
print(f"Accuracy: {means['accuracy']*100:.2f}%")
Accuracy: 86.91%
render(plot_contour(model=model, param_x='lr', param_y='beta1', metric_name='accuracy'))
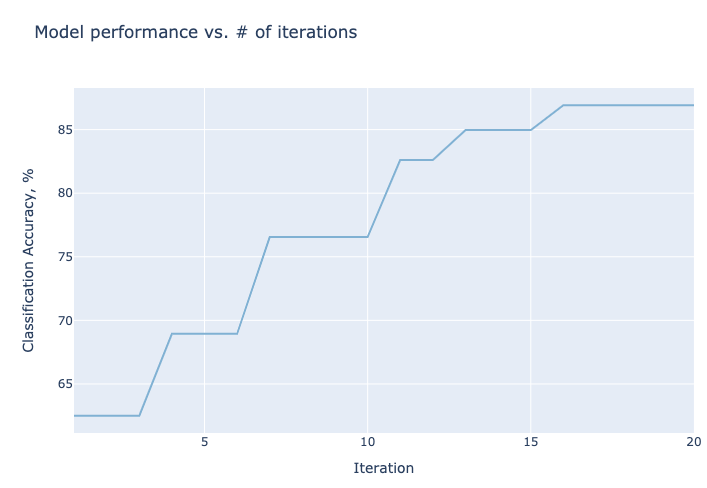
best_objectives = np.array([[trial.objective_mean*100 for trial in experiment.trials.values()]])
best_objective_plot = optimization_trace_single_method(
y=np.maximum.accumulate(best_objectives, axis=1),
title="Model performance vs. # of iterations",
ylabel="Classification Accuracy, %",
)
render(best_objective_plot)
3. Explaining CNNs¶
CNNs and neural networks in general are primarily used for prediction (i.e., we want the best prediction performance, and we might not care how we get it). However interpreting why a model makes certain predictions can be useful. Interpreting neural networks is an active area of research and it is difficult to do. There are a few main options:
Captum is a library for specifically interpreting PyTorch models. Captum contains a variety of state-of-the-art algorithms for interpreting models, see the docs here. Let’s use it quickly to find what areas of the following bitmoji are important for the models prediction of “tom”:
from captum.attr import GradientShap
from captum.attr import Occlusion
from captum.attr import visualization as viz
PATH = "models/bitmoji_cnn_augmented.pt"
model = bitmoji_CNN()
model.load_state_dict(torch.load(PATH))
model.eval();
image

image_tensor = transforms.functional.to_tensor(image.resize((IMAGE_SIZE, IMAGE_SIZE))).unsqueeze(0)
prediction = int(torch.sigmoid(model(image_tensor)) > 0.5)
print(f"Prediction: {train_dataset.classes[prediction]}")
Prediction: tom
# Occlusion
occlusion = Occlusion(model)
attributions_occ = occlusion.attribute(image_tensor,
strides = (1, 3, 3),
sliding_window_shapes=(1, 10, 10),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().detach().numpy(), (1,2,0)),
np.transpose(image_tensor.squeeze().detach().numpy(), (1,2,0)),
["original_image", "blended_heat_map"],
["all", "positive"],
titles = ["Original Image", "Occlusion"],
cmap="plasma",
fig_size=(6, 6),
alpha_overlay=0.7
)

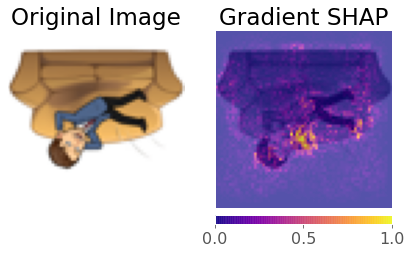
# Gradient SHAP
torch.manual_seed(2020); np.random.seed(2020)
gradient_shap = GradientShap(model)
rand_img_dist = torch.cat([image_tensor * 0, image_tensor * 1])
attributions_gs = gradient_shap.attribute(image_tensor,
n_samples=20,
stdevs=0.15,
baselines=rand_img_dist,
target=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_gs.squeeze().detach().numpy(), (1,2,0)),
np.transpose(image_tensor.squeeze().detach().numpy(), (1,2,0)),
["original_image", "blended_heat_map"],
["all", "absolute_value"],
titles = ["Original Image", "Gradient SHAP"],
cmap="plasma",
show_colorbar=True,
fig_size=(6, 6),
alpha_overlay=0.7)
4. Transfer Learning¶
Transfer learning is one of the most common techniques used in deep learning. It refers to using a model already trained on one task as a starting point for learning to perform another task. There are many famous deep learning architectures out there that have been very successful across a wide range of problem, e.g.: AlexNet, VGG, ResNet, Inception, MobileNet, etc.
Many of these models have been pre-trained on famous datasets like ImageNet (which contains 1.2 million labelled images with 1000 categories). So, why not use these famous architectures for our own tasks?! I like to think of there being three main kinds of transfer learning:
Use a pre-trained network out-of-the-box
Use a pre-trained network as a “feature extractor” and add new layers to it for your own task
Same as 2 but “fine-tune” the weights of the pre-trained network using your own data
We’ll briefly explore these options below.
4.1. Out-Of-The-Box¶
This is the simplest option of transfer learning. You basically download a model that performs the same task as you want to do and just use it to predict your own images. We can easily download famous models using the torchvision.models module. All models are available with pre-trained weights (based on ImageNet’s 224 x 224 images). For example:
densenet = models.densenet121(pretrained=True)
densenet.eval();
You can check out densenet’s architecture by printing it to screen but it’s huge so I won’t do that here. The layers can be accessed using the .named_children() method, the last one is the classification layer, a fully-connected layer outputting 1000 values (one for each ImageNet class):
list(densenet.named_children())[-1]
('classifier', Linear(in_features=1024, out_features=1000, bias=True))
The ImageNet class labels are stored in a file in this directory:
classes = json.load(open("data/imagenet_class_index.json"))
idx2label = [classes[str(k)][1] for k in range(len(classes))]
print("First 10 ImageNet classes:")
idx2label[:10]
First 10 ImageNet classes:
['tench',
'goldfish',
'great_white_shark',
'tiger_shark',
'hammerhead',
'electric_ray',
'stingray',
'cock',
'hen',
'ostrich']
Let’s try the model out on some random images (like my dog Evie):
image = Image.open('img/evie.png')
image

image = transforms.functional.to_tensor(image.resize((224, 224))).unsqueeze(0)
_, idx = torch.softmax(densenet(image), dim=1).topk(5)
print(f"Top 3 predictions: {[idx2label[_.item()] for _ in idx[0]]}")
Top 3 predictions: ['toy_poodle', 'Yorkshire_terrier', 'Maltese_dog', 'miniature_poodle', 'Shih-Tzu']
Not bad! Can we trick it with an image of me in a panda mask?
image = Image.open('img/panda-tom.png')
image

image = transforms.functional.to_tensor(image).unsqueeze(0)
_, idx = torch.softmax(densenet(image), dim=1).topk(5)
print(f"Top 5 predictions: {[idx2label[_.item()] for _ in idx[0]]}")
Top 5 predictions: ['mask', 'ski_mask', 'teddy', 'giant_panda', 'jersey']
Not bad either! Anyway, you get the point. This workflow is constrained to the architecture of the model, i.e., we can only predict the ImageNet classes at this point. What if I wanted to make prediction for another problem, say a binary classification problem? Read on.
4.2. Feature Extractor¶
In this method, we use a pre-trained model as a “feature extractor” which creates useful features for us that we can use to train some other model. We really have two options here:
Add some extra layers to the pre-trained network to suit our particular task
Pass training data through the network and save the output to use as features for training some other model
Let’s do approach 1 first. Let’s adapt densenet to predict our bitmoji data. I’m going to load the model, and then “freeze” all of its parameters (we don’t want to update them!):
densenet = models.densenet121(pretrained=True)
for param in densenet.parameters(): # Freeze parameters so we don't update them
param.requires_grad = False
We saw before that the last layer of densenet is a fully-connected linear layer Linear(in_features=1024, out_features=1000). We are going to do binary classification, so I’m going to replace this layer with my own layers (I’m using OrderedDict() here so I can name my layers, but you don’t have to do this):
new_layers = nn.Sequential(OrderedDict([
('new1', nn.Linear(1024, 500)),
('relu', nn.ReLU()),
('new2', nn.Linear(500, 1))
]))
densenet.classifier = new_layers
Let’s check that the last layer of our model is updated:
densenet.classifier
Sequential(
(new1): Linear(in_features=1024, out_features=500, bias=True)
(relu): ReLU()
(new2): Linear(in_features=500, out_features=1, bias=True)
)
Looks good! Now we need to train our new layers:
IMAGE_SIZE = 224
BATCH_SIZE = 128
# New dataloaders
train_dataset = torchvision.datasets.ImageFolder(root=TRAIN_DIR, transform=data_transforms)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
valid_dataset = torchvision.datasets.ImageFolder(root=VALID_DIR, transform=data_transforms)
valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=BATCH_SIZE, shuffle=True)
def trainer(model, criterion, optimizer, train_loader, valid_loader, device, epochs=5, verbose=True):
"""Simple training wrapper for PyTorch network."""
train_accuracy = []
valid_accuracy = []
for epoch in range(epochs): # for each epoch
train_batch_loss = 0
train_batch_acc = 0
valid_batch_loss = 0
valid_batch_acc = 0
# Training
for X, y in train_loader:
if device.type == 'cuda':
X, y = X.to(device), y.to(device)
optimizer.zero_grad()
y_hat = model(X).flatten()
y_hat_labels = torch.sigmoid(y_hat) > 0.5
loss = criterion(y_hat, y.type(torch.float32))
loss.backward()
optimizer.step()
train_batch_loss += loss.item()
train_batch_acc += (y_hat_labels == y).type(torch.float32).mean().item()
train_accuracy.append(train_batch_acc / len(train_loader))
# Validation
model.eval()
with torch.no_grad():
for X, y in valid_loader:
if device.type == 'cuda':
X, y = X.to(device), y.to(device)
y_hat = model(X).flatten()
y_hat_labels = torch.sigmoid(y_hat) > 0.5
loss = criterion(y_hat, y.type(torch.float32))
valid_batch_loss += loss.item()
valid_batch_acc += (y_hat_labels == y).type(torch.float32).mean().item()
valid_accuracy.append(valid_batch_acc / len(valid_loader))
model.train()
# Print progress
if verbose:
print(f"Epoch {epoch + 1}:",
f"Train Accuracy: {train_accuracy[-1]:.2f}.",
f"Valid Accuracy: {valid_accuracy[-1]:.2f}.")
return {"train_accuracy": train_accuracy, "valid_accuracy": valid_accuracy}
# We have a big model so this will take some time to run! If you have a GPU, things could be much faster!
densenet.to(device)
criterion = nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(densenet.parameters())
results = trainer(densenet, criterion, optimizer, train_loader, valid_loader, device, epochs=10)
Epoch 1: Train Accuracy: 0.60. Valid Accuracy: 0.63.
Epoch 2: Train Accuracy: 0.72. Valid Accuracy: 0.74.
Epoch 3: Train Accuracy: 0.75. Valid Accuracy: 0.72.
Epoch 4: Train Accuracy: 0.81. Valid Accuracy: 0.73.
Epoch 5: Train Accuracy: 0.80. Valid Accuracy: 0.69.
Epoch 6: Train Accuracy: 0.81. Valid Accuracy: 0.72.
Epoch 7: Train Accuracy: 0.86. Valid Accuracy: 0.78.
Epoch 8: Train Accuracy: 0.87. Valid Accuracy: 0.74.
Epoch 9: Train Accuracy: 0.89. Valid Accuracy: 0.73.
Epoch 10: Train Accuracy: 0.90. Valid Accuracy: 0.80.
Cool, we leveraged the power of densenet to get a really great model!
Now, you can use pre-trained model as arbitrary feature extractors, you don’t have to add on layers, you can just extract the output values of the network (well, you can extract values from any layer you like) and use those values as “features” to train another model. Below, I’m going to pass all my bitmoji data through the network and save the outputs:
def get_features(model, train_loader, valid_loader):
"""Extract output of squeezenet model"""
with torch.no_grad(): # turn off computational graph stuff
Z_train = torch.empty((0, 1024)) # Initialize empty tensors
y_train = torch.empty((0))
Z_valid = torch.empty((0, 1024))
y_valid = torch.empty((0))
for X, y in train_loader:
Z_train = torch.cat((Z_train, model(X)), dim=0)
y_train = torch.cat((y_train, y))
for X, y in valid_loader:
Z_valid = torch.cat((Z_valid, model(X)), dim=0)
y_valid = torch.cat((y_valid, y))
return Z_train.detach(), y_train.detach(), Z_valid.detach(), y_valid.detach()
densenet = models.densenet121(pretrained=True)
densenet.classifier = nn.Identity() # remove that last "classification" layer
Z_train, y_train, Z_valid, y_valid = get_features(densenet, train_loader, valid_loader)
Now we have some extracted features. Let’s train a classifier on the data, say, a LogisticRegression() model:
# Let's scale our data
scaler = StandardScaler()
Z_train = scaler.fit_transform(Z_train)
Z_valid = scaler.transform(Z_valid)
# Fit a model
model = LogisticRegression(max_iter=1000)
model.fit(Z_train, y_train)
print(f"Train accuracy: {model.score(Z_train, y_train) * 100:.2f}%")
print(f"Valid accuracy: {model.score(Z_valid, y_valid) * 100:.2f}%")
Train accuracy: 100.00%
Valid accuracy: 76.75%
So what did we just do:
We passed out bitmoji images through squeezenet and saved all the output values. Squeezenet outputs 1000 values per input. We had 1714 bitmoji images, so we extracted a tensor of shape
(1714, 1000)from squeezenet.So we now have a dataset of 1000 features and 1714 examples. Our target remains binary
("not_tom", "tom")=(0, 1). We used this data to train a logistic regression model. Cool!
4.3. Fine Tuning¶
Okay, this is the final and most common workflow of transfer learning. Above, we stacked some extra layers onto densenet and just trained those layer (we “froze” all of densenet’s weights). But we can also “fine tune” densenet’s weights if we like, to make it more suited to our data. We can choose to “fine tune” all of densenet’s ~8 million parameters, or just some of them. To do this, we use the same workflow as above, but we unfreeze the layers we wish to “fine-tune”:
# Load (but don't freeze!) the model
densenet = models.densenet121(pretrained=True)
# Replace classification layer
new_layers = nn.Sequential(OrderedDict([
('new1', nn.Linear(1024, 500)),
('relu', nn.ReLU()),
('new2', nn.Linear(500, 1))
]))
densenet.classifier = new_layers
# Move to GPU if available
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
densenet.to(device);
# Train the model (I did this on a GPU)
criterion = nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(densenet.parameters())
results = trainer(densenet, criterion, optimizer, train_loader, valid_loader, device, epochs=10)
Epoch 1: Train Accuracy: 0.79. Valid Accuracy: 0.61.
Epoch 2: Train Accuracy: 0.95. Valid Accuracy: 0.97.
Epoch 3: Train Accuracy: 0.98. Valid Accuracy: 0.98.
Epoch 4: Train Accuracy: 0.98. Valid Accuracy: 0.96.
Epoch 5: Train Accuracy: 0.98. Valid Accuracy: 0.96.
Epoch 6: Train Accuracy: 0.98. Valid Accuracy: 0.96.
Epoch 7: Train Accuracy: 0.99. Valid Accuracy: 0.97.
Epoch 8: Train Accuracy: 0.99. Valid Accuracy: 0.98.
Epoch 9: Train Accuracy: 0.99. Valid Accuracy: 0.94.
Epoch 10: Train Accuracy: 0.98. Valid Accuracy: 0.97.
Wow! By far our best results yet. You could also choose to fine-tune just some layers, for example, below I’ll freeze everything but the last two layers:
# Freeze all but the last two layers
for layer in densenet.features[:-2]:
for param in layer.parameters():
param.requires_grad = False
# Now re-train...
4.4. Transfer Learning Summary¶
Use a pre-trained model out-of-the-box (good if a model already exists for your problem).
Use a pre-trained model as a “feature extractor” (good if you want to adapt a pre-trained model for a specific problem).
Fine-tune a pre-trained model (same as 2 but generally yields better results, although at more computational cost).