
Chapter 1: Optimization & Gradient Descent¶
By Tomas Beuzen 🚀

Chapter Outline¶
Chapter Learning Objectives¶
Explain the difference between a model, loss function, and optimization algorithm in the context of machine learning.
Explain how the gradient descent algorithm works.
Apply gradient descent to linear and logistic regression.
Use
scipy.optimize.minimize()to minimize a function.
Imports¶
import numpy as np
import pandas as pd
from scipy.optimize import minimize
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.metrics import mean_squared_error, mean_absolute_error
from utils.plotting import *
1. Optimization and Machine Learning¶
In data science and computer science, we optimize a lot of stuff. For example, in linear regression we optimize for the intercept and coefficients of our model, in clustering algorithms like k-means we optimize our clusters, in neural networks we optimize the weights in our network (more on that in a later chapter!), etc.
In one sentence, “optimization” simply refers to minimizing/maximizing a function. For example, what value of \(x\) minimizes the function \(f(x) = (x-2)^2 + 5\)? What is the minimum value? Answers: \(x=2\), and \(f(x)=5\).
If you’re reading this, you’re likely already familiar with machine learning. You can start to think of machine learning as a three-step process:
Choose your model: controls the space of possible functions that map \(X\) to \(y\) (e.g., a linear model can only learn linear functions)
Choose your loss function: tells us how to compare these various functions (e.g., is \(y=5 + 2x_1+3x_2\) a better model than \(y=1 + 10x_1-x_2\)?)
Choose your optimization algorithm: finds the minimum of the loss function (e.g., what is the optimum value of \(w_0\) and \(w_1\) in \(y=w_0 + w_1x\)?)
In this chapter we’ll be taking a look at optimization in detail and a particular optimization algorithm known as gradient descent.
2. Loss Functions¶
Loss functions (also often called “objective functions” or “cost functions”, although some debate that these are slightly different things) are what we use to map the performance of a model to a real number and it’s the thing we want to optimize! For example, here’s the mean squared error (MSE), which is a common loss function:
Where \(y_i\) is the actual response and \(\hat{y_i}\) is the predicted response.
Consider a simple linear regression model \(\hat{y_i} = w_0 + w_1x_i\), then our loss function is:
The optimization problem here is to find the values of \(w_0\) and \(w_1\) that minimizes the MSE.
3. Optimizing Linear Regression¶
I’m going to build up the intuition for optimization in a practical and visual way with the help of our old friend linear regression. If you’d prefer a more mathematical approach I encourage you to check out my colleague Mike Gelbart’s lecture on Youtube Thinking about Optimization or Chapter 7 of Mathematics for Machine Learning, by Deisenroth et al..
We’ll use a dataset of Pokemon “attack” and “defense” stats to do this, I’m going to start with just 10 observations:
df = (pd.read_csv("data/pokemon.csv", usecols=['name', 'defense', 'attack'], index_col=0)
.head(10)
.sort_values(by='defense')
.reset_index()
)
x = df['defense']
y = df['attack']
df
| name | attack | defense | |
|---|---|---|---|
| 0 | Caterpie | 30 | 35 |
| 1 | Charmander | 52 | 43 |
| 2 | Bulbasaur | 49 | 49 |
| 3 | Charmeleon | 64 | 58 |
| 4 | Ivysaur | 62 | 63 |
| 5 | Squirtle | 48 | 65 |
| 6 | Charizard | 104 | 78 |
| 7 | Wartortle | 63 | 80 |
| 8 | Blastoise | 103 | 120 |
| 9 | Venusaur | 100 | 123 |
Throughout this chapter, I’m leveraging plotting scripts I imported from
utils.plotting. I abstracted the code out of the notebook to avoid cluttering the material here and because how I made these plots is not important - but feel free to check out the source code if you wish!
plot_pokemon(x, y)
Recall simple linear regression: \(\hat{y_i} = w_0 + w_1x_i\) (where \(w_0\) is the intercept and \(w_1\) is the slope coefficient). If we assume (\(w_0\), \(w_1\)) = (10, 0.5) then we would have:
y_hat = 10 + 0.5 * x
Let’s plot that result:
plot_pokemon(x, y, y_hat)
The fit is not very good… We need to optimize it! A loss function can help quantify the fit of our model and we want to find the parameters of our model that minimize the loss function. We’ll use mean-squared-error (MSE) as our loss function:
Where \(n\) is the number of data points we have (10 in our case). We’ll use the sklearn function mean_squared_error() which I imported at the top of the notebook to calculate MSE for us:
mean_squared_error(y, y_hat)
680.75
So this is the MSE across all training examples. For now, let’s assume the intercept is 0 (\(w_0 = 0\)) and just focus on optimizing the slope (\(w_1\)). One thing we could do is try many different values for the slope and find the one that minimizes the MSE:
slopes = np.arange(0.4, 1.65, 0.05)
mse = pd.DataFrame({"slope": slopes,
"MSE": [mean_squared_error(y, m * x) for m in slopes]})
mse
| slope | MSE | |
|---|---|---|
| 0 | 0.40 | 1770.0760 |
| 1 | 0.45 | 1478.6515 |
| 2 | 0.50 | 1216.7500 |
| 3 | 0.55 | 984.3715 |
| 4 | 0.60 | 781.5160 |
| 5 | 0.65 | 608.1835 |
| 6 | 0.70 | 464.3740 |
| 7 | 0.75 | 350.0875 |
| 8 | 0.80 | 265.3240 |
| 9 | 0.85 | 210.0835 |
| 10 | 0.90 | 184.3660 |
| 11 | 0.95 | 188.1715 |
| 12 | 1.00 | 221.5000 |
| 13 | 1.05 | 284.3515 |
| 14 | 1.10 | 376.7260 |
| 15 | 1.15 | 498.6235 |
| 16 | 1.20 | 650.0440 |
| 17 | 1.25 | 830.9875 |
| 18 | 1.30 | 1041.4540 |
| 19 | 1.35 | 1281.4435 |
| 20 | 1.40 | 1550.9560 |
| 21 | 1.45 | 1849.9915 |
| 22 | 1.50 | 2178.5500 |
| 23 | 1.55 | 2536.6315 |
| 24 | 1.60 | 2924.2360 |
plot_grid_search(x, y, slopes, mean_squared_error)
It looks like a slope of 0.9 gives us the lowest MSE (~184.4). But you can imagine that this “grid search” approach quickly becomes computationally intractable as the size of our data set and number of model parameters increases! So we need a better way to optimize our parameters… we need an optimization algorithm! The one we’ll focus on in this chapter is Gradient Descent.
4. Gradient Descent With One Parameter¶
Gradient descent is an optimization algorithm that can help us optimize our loss function more efficiently than the “manual” approach we tried above. As the name suggest, we are going to leverage the gradient of our loss function to help us optimize our model parameters. The gradient is just a vector of (partial) derivatives of the loss function w.r.t the model parameters. Sounds complicated but it’s not at all (as I’ll hopefully show you).
In plain English, the gradient will tell us two things:
Which direction to move our parameter in to decrease loss (i.e., should we increase or decrease its value?)
How far to move it (i.e., should we adjust it by 0.1 or 2 or 50 etc.?)
If you need a refresher on gradients, check out Appendix A: Gradients Review.
Let’s forget about the intercept now and just work with this simple linear model: \(\hat{y_i}=wx_i\). For this model, the loss function has the form:
The gradient of this function with respect to the parameter \(w\) is:
Let’s code that up and calculate the gradient of our loss function at a slope of \(w = 0.5\):
def gradient(x, y, w):
return 2 * (x * (w * x - y)).mean()
gradient(x, y, w=0.5)
-4942.8
So this is the gradient across all training examples and tells us how to adjust \(w\) to reduce the MSE loss over all training examples! Recall from calculus that the gradient actually points in the direction of steepest ascent (read more in Appendix A: Gradients Review). We want to move in the direction of steepest descent (the negative of the gradient) to reduce our loss. For example, the above gradient is negative, but we obviously need to increase the value of our slope (\(w\)) to reduce our loss as you can see here:
plot_gradient_m(x, y, 0.5, mse["slope"], mse["MSE"], gradient)
The amount we adjust our slope each iteration is controlled by a “learning rate”, denoted \(\alpha\) (note the minus in the equation below which accounts for flipping the sign of the gradient as discussed above):
\(\alpha\) is a hyperparameter that can be optimized, typical values range from 0.001 to 0.9. With the math out of the way, we’re now ready to use gradient descent to optimize our slope. Gradient descent is an iterative algorithm, meaning that we keep repeating it until we meet some stopping criteria. Typically we stop gradient descent when:
the step size is smaller than some pre-defined threshold; or,
a certain number of steps is completed.
So the pseudo code for gradient descent boils down to this:
1. begin with with some arbitrary w
while stopping criteria not met:
2. calculate mean gradient across all examples
3. update w based on gradient and learning rate
4. repeat
Let’s go ahead and implement that now:
def gradient_descent(x, y, w, alpha, ϵ=2e-4, max_iterations=5000, print_progress=10):
"""Gradient descent for optimizing slope in simple linear regression with no intercept."""
print(f"Iteration 0. w = {w:.2f}.")
iterations = 1 # init iterations
dw = 2 * ϵ # init. dw
while abs(dw) > ϵ and iterations <= max_iterations:
g = gradient(x, y, w) # calculate current gradient
dw = alpha * g # change in w
w -= dw # adjust w based on gradient * learning rate
if iterations % print_progress == 0: # periodically print progress
print(f"Iteration {iterations}. w = {w:.2f}.")
iterations += 1 # increase iteration
print("Terminated!")
print(f"Iteration {iterations - 1}. w = {w:.2f}.")
gradient_descent(x, y, w=0.5, alpha=0.00001)
Iteration 0. w = 0.50.
Iteration 10. w = 0.80.
Iteration 20. w = 0.88.
Iteration 30. w = 0.91.
Iteration 40. w = 0.92.
Terminated!
Iteration 45. w = 0.92.
Let’s take a look at the journey our slope parameter of our simple linear model went on during its optimization:
plot_gradient_descent(x, y, w=0.5, alpha=0.00001)
Now let’s see what happens if we increase the learning rate:
gradient_descent(x, y, w=0.5, alpha=0.00005, print_progress=2)
Iteration 0. w = 0.50.
Iteration 2. w = 0.85.
Iteration 4. w = 0.91.
Iteration 6. w = 0.92.
Iteration 8. w = 0.92.
Terminated!
Iteration 9. w = 0.92.
plot_gradient_descent(x, y, w=0.5, alpha=0.00005)
Let’s increase a little more:
gradient_descent(x, y, w=0.5, alpha=0.00015)
Iteration 0. w = 0.50.
Iteration 10. w = 0.89.
Iteration 20. w = 0.92.
Iteration 30. w = 0.92.
Terminated!
Iteration 33. w = 0.92.
plot_gradient_descent(x, y, w=0.5, alpha=0.00015)
If our learning rate is too high, we’ll overshoot and never converge (i.e., we’ll diverge)!
gradient_descent(x, y, w=0.5, alpha=0.00018, max_iterations=4, print_progress=1)
Iteration 0. w = 0.50.
Iteration 1. w = 1.39.
Iteration 2. w = 0.39.
Iteration 3. w = 1.52.
Iteration 4. w = 0.25.
Terminated!
Iteration 4. w = 0.25.
plot_gradient_descent(x, y, w=0.5, alpha=0.00018, max_iterations=4)
Cool, we just implemented gradient descent from scratch! In the next seciton, we’ll try optimizing for two parameters, the intercept and slope of a simple linear regression model, simultaneously…
5. Gradient Descent With Two Parameters¶
Most of the models you’ll be working with will have more than just one parameter to update - neural networks typically have hundreds, thousands, and even millions of parameters! So, let’s extend the above workflow to two parameters, the intercept (\(w_0\)) and the slope (\(w_1\)). Just to help you get a visual of what’s going on, let’s take our “manual grid search approach” from earlier and make a plot of it but this time with two parameters:
slopes = np.arange(0, 2.05, 0.05)
intercepts = np.arange(-30, 31, 2)
plot_grid_search_2d(x, y, slopes, intercepts)
Above is the surface of MSE for different values of intercept (\(w_0\)) and slope (\(w_1\)). The approach for implementing gradient descent is exactly as before, but we’re operating on two parameters now and the gradient of the intercept is a little different to the slope:
Let’s define a function that returns these two gradients (partial derivatives) of the slope and intercept.
“Gradient” is technically the vector of all partial derivatives of the loss function with respect to all the model weights. But I use the term fairly loosely to mean either the vector of all partial derivatives, or just a particular partial derivative, which you can infer from the given context.
def gradient(x, y, w):
grad_w0 = (1/len(x)) * 2 * sum(w[0] + w[1] * x - y)
grad_w1 = (1/len(x)) * 2 * sum(x * (w[0] + w[1] * x - y))
return np.array([grad_w0, grad_w1])
gradient(x, y, w=[10, 0.5])
array([ -43.6, -3514.8])
You can already see that the gradient of our slope is orders of magnitude larger than our intercept… we’ll look more at this issue shortly. For now let’s re-write our gradient descent function from earlier. It’s almost exactly the same as before, but now we are updating the slope and the intercept each iteration:
def gradient_descent(x, y, w, alpha, ϵ=2e-4, max_iterations=5000, print_progress=10):
"""Gradient descent for optimizing simple linear regression."""
print(f"Iteration 0. Intercept {w[0]:.2f}. Slope {w[1]:.2f}.")
iterations = 1 # init iterations
dw = np.array(2 * ϵ) # init. dw
while abs(dw.sum()) > ϵ and iterations <= max_iterations:
g = gradient(x, y, w) # calculate current gradient
dw = alpha * g # change in w
w -= dw # adjust w based on gradient * learning rate
if iterations % print_progress == 0: # periodically print progress
print(f"Iteration {iterations}. Intercept {w[0]:.2f}. Slope {w[1]:.2f}.")
iterations += 1 # increase iteration
print("Terminated!")
print(f"Iteration {iterations - 1}. Intercept {w[0]:.2f}. Slope {w[1]:.2f}.")
gradient_descent(x, y, w=[10, 0.5], alpha=0.00001)
Iteration 0. Intercept 10.00. Slope 0.50.
Iteration 10. Intercept 10.00. Slope 0.71.
Iteration 20. Intercept 10.00. Slope 0.77.
Iteration 30. Intercept 10.00. Slope 0.79.
Iteration 40. Intercept 10.00. Slope 0.80.
Terminated!
Iteration 43. Intercept 10.00. Slope 0.80.
Hmm… our algorithm worked but our intercept never changed. Let’s take a look at what happened:
plot_gradient_descent_2d(x, y, w=[10, 0.5], m_range=np.arange(0, 2.05, 0.05), b_range=np.arange(-30, 31, 2), alpha=0.00001)
Only the slope changed in value (we see a vertical line in the plot above, with no change in the intercept parameter). That’s because the slope gradient is wayyyyy bigger than the intercept gradient. Let’s see what the real value of these params are using sklearn’s implementation:
m = LinearRegression().fit(np.atleast_2d(x).T, y)
print(f"sklearn inter = {m.intercept_:.2f}")
print(f"sklearn slope = {m.coef_[0]:.2f}")
sklearn inter = 14.02
sklearn slope = 0.75
So we were a bit off in our implementation. We need to get the slope and intercept on the same scale…
5.1. Scaling¶
There are a few ways we can solve our problem above. The most common way is to simply scale your features before gradient descent:
scaler = StandardScaler()
x_scaled = scaler.fit_transform(np.atleast_2d(x).T).flatten()
x_scaled
array([-1.28162658, -0.99995041, -0.78869328, -0.47180759, -0.29575998,
-0.22534094, 0.23238284, 0.30280188, 1.71118274, 1.81681131])
slopes = np.arange(-60, 101, 2)
intercepts = np.arange(-30, 171, 2)
plot_grid_search_2d(x_scaled, y, slopes, intercepts)
Now let’s check a random gradient after scaling:
gradient(x_scaled, y, w=[10, 0.5])
array([-115. , -41.54718577])
Great, our gradients are on a similar scale now, let’s retry gradient descent with our scaled data:
gradient_descent(x_scaled, y, w=[10, 2], alpha=0.2)
Iteration 0. Intercept 10.00. Slope 2.00.
Iteration 10. Intercept 67.15. Slope 21.16.
Iteration 20. Intercept 67.50. Slope 21.27.
Terminated!
Iteration 25. Intercept 67.50. Slope 21.27.
m = LinearRegression().fit(np.atleast_2d(x_scaled).T, y)
print(f"sklearn inter = {m.intercept_:.2f}")
print(f"sklearn slope = {m.coef_[0]:.2f}")
sklearn inter = 67.50
sklearn slope = 21.27
Matches perfectly! Let’s look at the journey our parameters went on:
plot_gradient_descent_2d(x_scaled, y, w=[-10, -50], alpha=0.2, m_range=np.arange(-60, 101, 2), b_range=np.arange(-30, 171, 2), markers=True)
Just to drive the point home, note once again that changing the learning rate will affect our optimization (I added some markers on this plot to show you that we’re bouncing back-and-forth):
plot_gradient_descent_2d(x_scaled, y, w=[-10, -50], alpha=0.9, m_range=np.arange(-60, 101, 2), b_range=np.arange(-30, 171, 2), markers=True)
6. Other Optimization Algorithms¶
When you saw us using gradients earlier on you might have thought, why not just set the derivative to 0 and solve? You sure could do this! And in general, if a closed form solution exists for your problem, you should typically use it. However:
Most problems in ML do not have a closed-form solution;
Even if a closed form solution exists (e.g., linear regression), it can be extremely computationally expensive to compute if your dataset is large (many observations and/or many features).
In these cases, optimization algorithms like gradient descent may be appropriate choices. In actuality you will almost never use vanilla gradient descent in practice because it’s actually very slow (but the intuition behind it forms the basis of tons of optimization algorithms so it’s a great place to start learning). We’ll look at a computationally lighter version of gradient descent next chapter (stochastic gradient descent) and there are also many other algorithms available! You can explore the scipy function minimize to play around with some of these algorithms:
from scipy.optimize import minimize
Here was our gradient descent implementation from earlier:
gradient_descent(x_scaled, y, w=[10, 2], alpha=0.2)
Iteration 0. Intercept 10.00. Slope 2.00.
Iteration 10. Intercept 67.15. Slope 21.16.
Iteration 20. Intercept 67.50. Slope 21.27.
Terminated!
Iteration 25. Intercept 67.50. Slope 21.27.
Scipy’s minimize function takes as argument the function to minimize, the function’s gradient and the starting parameter values. For a linear regression model, the MSE loss and gradient take the general form:
I’ve coded up that up using matrix multiplication:
def mse(w, X, y):
"""Mean squared error."""
return np.mean((X @ w - y) ** 2)
def mse_grad(w, X, y):
"""Gradient of mean squared error."""
return 2 * (X.T @ (X @ w) - X.T @ y) / len(X)
Now we can call minimize:
w = np.array([10, 2])
x = np.hstack((np.ones((len(x), 1)), x_scaled[:, None])) # appening a column of 1's for the intercept
minimize(mse, w, jac=mse_grad, args=(x, y))
fun: 155.4842457601904
hess_inv: array([[ 0.55050293, -0.15066824],
[-0.15066824, 0.94949707]])
jac: array([0.00000000e+00, 1.70530257e-14])
message: 'Optimization terminated successfully.'
nfev: 5
nit: 2
njev: 5
status: 0
success: True
x: array([67.5 , 21.27359289])
minimize(mse, w, jac=mse_grad, args=(x, y)).x # these are the weights, it's a bit confusing because they are called "x"
array([67.5 , 21.27359289])
There are plenty of methods you can look into (most give the same answers):
for method in ["CG", "L-BFGS-B", "SLSQP", "TNC"]:
print(f"Method: {method}, Weights: {minimize(mse, w, jac=mse_grad, args=(x, y), method=method).x}")
Method: CG, Weights: [67.5 21.27359289]
Method: L-BFGS-B, Weights: [67.5 21.27359289]
Method: SLSQP, Weights: [67.5 21.27359289]
Method: TNC, Weights: [67.5 21.27359287]
7. Optimizing Logistic Regression¶
In this final section section I’m going to demonstrate optimizing a Logistic Regression model to drive home some of the points we learned in this chapter. I’m going to sample 70 “legendary” pokemon (which are typically super-powered) and “non-legendary” pokemon from our dataset:
df = pd.read_csv("data/pokemon.csv", index_col=0, usecols=['name', 'defense', 'legendary']).reset_index()
leg_ind = df["legendary"] == 1
df = pd.concat(
(df[~leg_ind].sample(sum(leg_ind), random_state=123), df[leg_ind]),
ignore_index=True,
).sort_values(by='defense')
df.head(10)
| name | defense | legendary | |
|---|---|---|---|
| 23 | Sunkern | 30 | 0 |
| 2 | Gastly | 30 | 0 |
| 127 | Cosmog | 31 | 1 |
| 25 | Mankey | 35 | 0 |
| 5 | Remoraid | 35 | 0 |
| 6 | Kirlia | 35 | 0 |
| 60 | Tyrogue | 35 | 0 |
| 67 | Poochyena | 35 | 0 |
| 58 | Buizel | 35 | 0 |
| 11 | Noibat | 35 | 0 |
x = StandardScaler().fit_transform(df[['defense']]).flatten() # we saw before the standardizing is a good idea for optimization
y = df['legendary'].to_numpy()
plot_logistic(x, y)
We’ll be using the “trick of ones” to help us implement these computations efficiently. For example, consider the following simple linear regression model with an intercept and a slope:
Let’s represent that in matrix form:
Now we can calculate \(\mathbf{y}\) using matrix multiplication and the “matmul” Python operator:
w = np.array([2, 3])
X = np.array([[1, 5], [1, 3], [1, 4]])
X @ w
array([17, 11, 14])
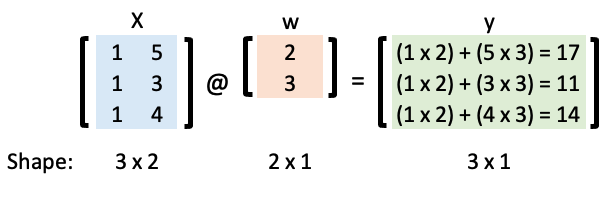
We’re going to create a logistic regression model to classify a Pokemon as “legendary” or not. Recall that in logistic regression we map our linear model to a probability:
For classification purposes, we typically then assign this probability to a discrete class (0 or 1) based on a threshold (0.5 by default):
Let’s code that up:
def sigmoid(x, w, output="soft", threshold=0.5):
p = 1 / (1 + np.exp(-x @ w))
if output == "soft":
return p
elif output == "hard":
return np.where(p > threshold, 1, 0)
For example, if \(w = [0, 0]\):
ones = np.ones((len(x), 1))
X = np.hstack((ones, x[:, None])) # add column of ones for the intercept term
w = [-1, 3]
y_soft = sigmoid(X, w)
y_hard = sigmoid(X, w, "hard")
plot_logistic(x, y, y_soft, threshold=0.5)
Let’s calculate the accuracy of the above model:
def accuracy(y, y_hat):
return (y_hat == y).sum() / len(y)
accuracy(y, y_hard)
0.7142857142857143
Just like in the linear regression example earlier, we want to optimize the values of our weights! We need a loss function! We use the log loss (cross-entropy loss) to optimize logistic regression. Here’s the loss function and its gradient (see Appendix B: Logistic Loss if you want to learn more about these, they’re actually quite simple!):
def logistic_loss(w, X, y):
return -(y * np.log(sigmoid(X, w)) + (1 - y) * np.log(1 - sigmoid(X, w))).mean()
def logistic_loss_grad(w, X, y):
return (X.T @ (sigmoid(X, w) - y)) / len(X)
w_opt = minimize(logistic_loss, np.array([-1, 1]), jac=logistic_loss_grad, args=(X, y)).x
w_opt
array([0.05153269, 1.34147091])
Let’s check our solution against the sklearn implementation:
lr = LogisticRegression(penalty='none').fit(x.reshape(-1, 1), y)
print(f"w0: {lr.intercept_[0]:.2f}")
print(f"w1: {lr.coef_[0][0]:.2f}")
w0: 0.05
w1: 1.34
This is what the optimized model looks like:
y_soft = sigmoid(X, w_opt)
plot_logistic(x, y, y_soft, threshold=0.5)
y_hard = sigmoid(X, w_opt, "hard")
accuracy(y, y_hard)
0.8
Checking that against the sklearn model:
lr.score(x.reshape(-1, 1), y)
0.8
I mean, that’s so cool! We replicated the sklearn behavour from scratch!!!! By the way, I’ve been doing things in 2D here because it’s easy to visualize, but let’s double check that we can work in more dimensions by using attack, defense and speed to classify a Pokemon as legendary or not:
df = pd.read_csv("data/pokemon.csv", index_col=0, usecols=['name', 'defense', 'attack', 'speed', 'legendary']).reset_index()
leg_ind = df["legendary"] == 1
df = pd.concat(
(df[~leg_ind].sample(sum(leg_ind), random_state=123), df[leg_ind]),
ignore_index=True,
)
df.head()
| name | attack | defense | speed | legendary | |
|---|---|---|---|---|---|
| 0 | Roggenrola | 75 | 85 | 15 | 0 |
| 1 | Gible | 70 | 45 | 42 | 0 |
| 2 | Gastly | 35 | 30 | 80 | 0 |
| 3 | Minun | 40 | 50 | 95 | 0 |
| 4 | Marill | 20 | 50 | 40 | 0 |
x = StandardScaler().fit_transform(df[["defense", "attack", "speed"]])
X = np.hstack((np.ones((len(x), 1)), x))
y = df["legendary"].to_numpy()
w_opt = minimize(logistic_loss, np.zeros(X.shape[1]), jac=logistic_loss_grad, args=(X, y), method="L-BFGS-B").x
w_opt
array([-0.23259512, 1.33705304, 0.52029373, 1.36780376])
lr = LogisticRegression(penalty="none").fit(x, y)
print(f"w0: {lr.intercept_[0]:.2f}")
for n, w in enumerate(lr.coef_[0]):
print(f"w{n+1}: {w:.2f}")
w0: -0.23
w1: 1.34
w2: 0.52
w3: 1.37
Looks good to me!